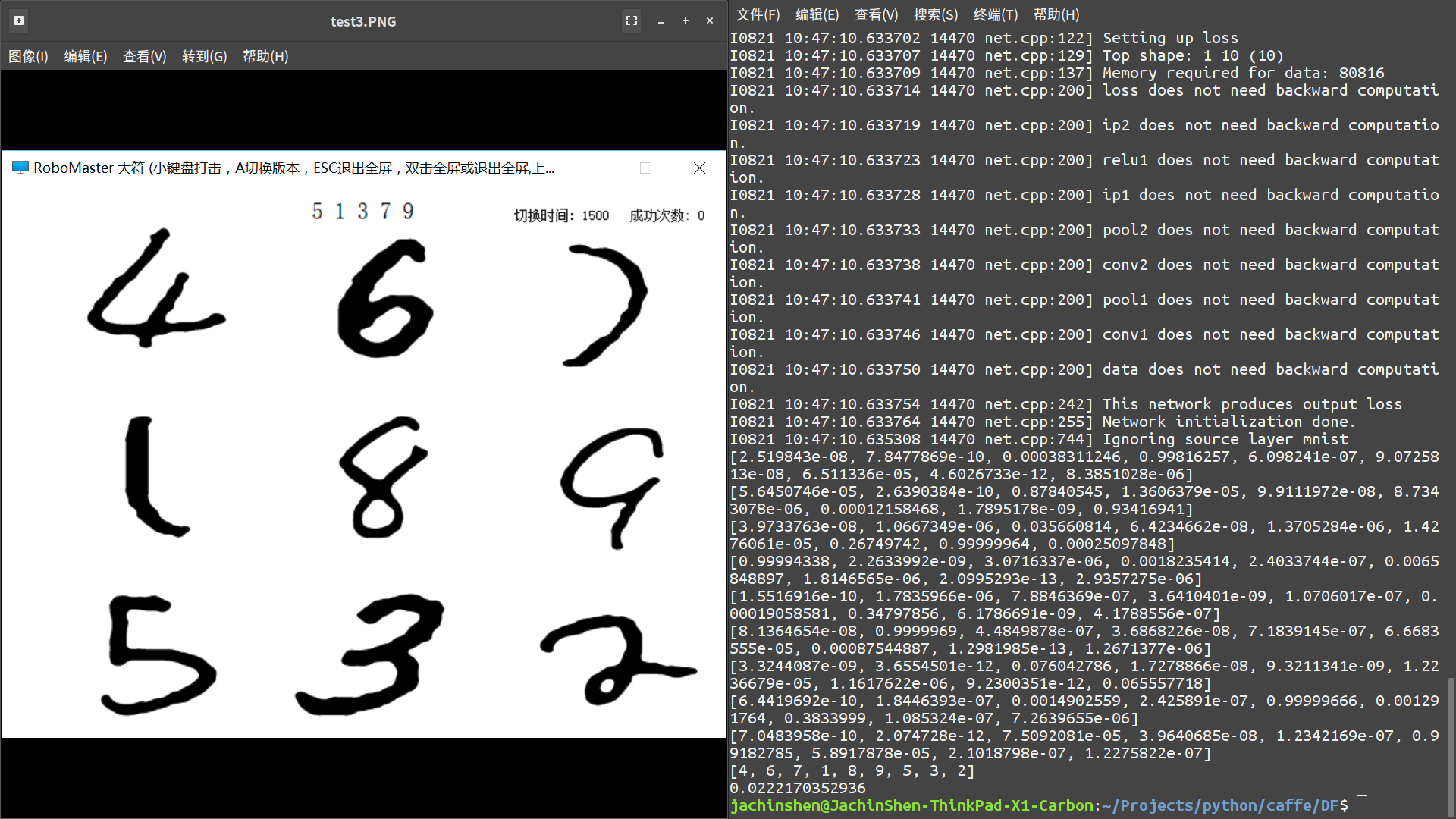
在2017年的 RoboMaster 比赛中,增加了一个全新的机关,地区赛中称为大神符,全国赛中称为大能量机关。需要根据数码管的数字击打对应的手写数字,连续多次击打成功才可以激活。
当中,手写数字的识别正好切合了当前最火的卷积神经网络。各种深度学习框架的官方教程中对于训练和测试十分详细,但是最后一步的部署往往一笔带过。
故本文介绍如何部署 Caffe 深度学习模型。
部署 Caffe 深度学习模型
Caffe 是一个开源的深度学习框架,它通过文本文件构建卷积神经网络的结构,可以在 Python 和 C++ 中部署。
输入层和输出层结构修改
在 Caffe 官方 examples/mnist/lenet_train_test.prototxt 中, 测试阶段输入层为:
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_test_lmdb"
batch_size: 100
backend: LMDB
}
}
它的输入层直接指定了 lmdb 格式的数据,但是在部署的时候,只需要处理少量数据,没有必要将原始数据转换为 lmdb 格式。
为了一次只传入一组数据,需要将输入层修改为:
layer {
name: "data"
type: "Input"
top: "data"
input_param{ shape: { dim: 1 dim: 1 dim: 28 dim: 28 } }
}
将输入数据的尺寸指定为 1 x 1 x 28 x 28 ,即一张处理过的 28 x 28 的图片(后面会详细介绍如何处理才可以适应输入层)。
注:没有指定 phase, 所以这个模型只适用于部署。
同理,测试阶段输出层为:
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}
由于实际部署中就是需要得到数据的标签,修改为:
layer {
name: "loss"
type: "Softmax"
bottom: "ip2"
top: "loss"
}
去除了底部的标签和 loss 评估,通过读取 loss 层就可以得到概率。
Python
对于新手推荐使用 Python ,配置简单,使用方便。
配置Pycaffe
对于 Pycaffe 的配置,网上的资料很详细,在此不再赘述。
加载网络
model = './lenet_deploy.prototxt'#读取模型
weights = './lenet_iter_10000.caffemodel'#读取参数
caffe.set_mode_cpu;#设置成cpu模式,可改成gpu
net = caffe.Net(model, weights, caffe.TEST)#加载网络
这一步会加载好神经网络和已经训练好的参数。
Net 构造中的最后一个参数表示网络属于 TEST ,即测试阶段,这有可能影响网络的结构,需要确保在网络结构文本文件中,测试阶段的模型适合部署,特别是输入层和输出层。
图像预处理
原图如下:

img_raw = cv2.imread('test1.PNG',0)#读灰度图
_,img_raw = cv2.threshold(img_raw, 128, 255, cv2.THRESH_BINARY_INV)#二值化
img_raw = cv2.normalize(img_raw.astype('float'), None, 0.0, 1.0, cv2.NORM_MINMAX)
#归一化
将原始图像处理成 MNIST 数据集中图片的格式,便于传入输入层。
提取数字区域并前传预测
results = [[0 for col in range(10)] for row in range(9)]#中间结果矩阵
result = [0,0,0,0,0,0,0,0,0]#最终结果矩阵
for i in range(0,3):
for j in range(0,3):
img = img_raw[100+225*i:325+225*i,318*j:318+318*j]#截取测试图中九宫格部分
img = cv2.resize(img, dsize=(28, 28), interpolation = cv2.INTER_LINEAR )
#压缩为28*28大小
img = img.reshape((1,1,28,28))#转换为1*1*28*28维向量,便于数据输入
net.blobs['data'].data[...] = img #将图片载入到blob中
out = net.forward()#前传
results[3*i+j] = net.blobs['loss'].data[0].flatten()
#取出最后一层(Softmax)属于某个类别的概率值
for i in range(1,10):
tmp = [0,0,0,0,0,0,0,0,0]
for j in range(0,9):
tmp[j] = results[j][i]
print(tmp)
result[tmp.index(max(tmp))] = i#取出每个数字最大概率所在的九宫格位置
print(result)
这步真正使用到了深度学习网络,进行了一次前传,得到概率,实现了从图片到数字的映射。
之后的代码是专门为 RoboMaster 的大神符设计的。(对此不感兴趣的读者,可以直接跳到如何在 C++ 中部署 Caffe )
因为九宫格的数字各不相同,可以利用这一点,即使有个别数字较难识别,也可以得到正确结果。原本给出的所有数据可以认为是每个位置为哪个数字的概率矩阵,但是如果考虑到数字不重复的前提,换个方向看,就可以认为是每个数字在哪个位置的概率矩阵。

比如,在此图中,右上角的 7 很难识别,但是依然能给出正确结果。
实际测试中,右上的图片,被认为是 7 的概率只有 7.6%,而 2 的概率却有 87.8%。
但是,2 在右下的概率有 93.4%,所以右下是 2 更有把握;同时,因为其他宫格不是 7 ,所以 7 在其他宫格的概率更小,就可以认为右上是 7 。
这样,即使有一个宫格的图片很难识别,仍然可以得到正确结果。
C++
Caffe 本来就是用 C++ 写成的,所以只要调用它的 C++ 函数就可以实现部署了。
编译环境
为了开发方便,可以直接在编译安装 Caffe 的目录下的 examples 里建立工程,然后再 make 一次,就可以在 build/bin 里找到相应的可执行文件。
两个函数
int get_blob_index(boost::shared_ptr< Net<float> > & net, char *query_blob_name)
{
std::string str_query(query_blob_name);
vector< string > const & blob_names = net->blob_names();
for( unsigned int i = 0; i != blob_names.size(); ++i )
{
if( str_query == blob_names[i] )
{
return i;
}
}
return -1;
}
这个函数顾名思义,就是通过 blob 的名字得到 id。第一个参数是深度学习网络的指针,如何获取深度学习网络的对象之后会讲,第二个参数是 blob 名字的字符串。
void caffe_forward(boost::shared_ptr< Net<float> > & net, float *data_ptr)
{
//get the id of data layer from the name"data"
//you can replace the name with your own data layer or any layer you want to put data
char query_blob_name[10] = "data"; /* data, conv1, pool1, norm1, fc6, prob, etc */
unsigned int blob_id = get_blob_index(net, query_blob_name);
//or, you can directly give the blob_id, like blob_id=0;(0 is common for data layer)
cout<<"data blob id:"<<blob_id<<endl;
Blob<float>* input_blobs = net->input_blobs()[blob_id];
switch (Caffe::mode())
{
case Caffe::CPU:
memcpy(input_blobs->mutable_cpu_data(), data_ptr,
sizeof(float) * input_blobs->count());
break;
//if you haven't installed CUDA, comment this case
case Caffe::GPU:
cudaMemcpy(input_blobs->mutable_gpu_data(), data_ptr,
sizeof(float) * input_blobs->count(), cudaMemcpyHostToDevice);
break;
//comment to here
default: break;
}
//net->ForwardPrefilled();
net->Forward();
}
这个函数会载入数据并进行一次前传,第一个参数是深度学习网络的指针,第二个参数是数据的指针。如果没有安装 CUDA,需要注释掉 GPU 模式来防止编译报错。
值得注意的是,Caffe 会根据输入层的大小读取相应大小的数组,所以需要数据连续存放在数组里,再传入数组的指针。因此不能直接传入 cv::Mat 的数据指针,因为 Mat 的数据有可能是分散的。
主函数
加载模型
char proto[100] = "your_path/lenet_deploy.prototxt"; /* 加载CaffeNet的配置 */
Phase phase = TEST; /* or TRAIN */
Caffe::set_mode(Caffe::CPU);
boost::shared_ptr< Net<float> > net(new caffe::Net<float>(proto, phase));
char model[100] = "your_path/lenet_iter_10000.caffemodel";//load arguments of model
net->CopyTrainedLayersFrom(model);
这一步加载好网络模型并载入训练过的参数,这样 net 就指向了训练好的模型。
处理图片

要处理单独的一张 5,代码如下:
Mat img = imread("/home/jachinshen/Apps/caffe/examples/cpp_mnist/_00175.png", 0);
resize(img, img, Size(28, 28));
threshold(img, img, 128, 1, THRESH_BINARY_INV);
先是读取灰度图,然后缩放为 28 x 28 大小,最后再二值化为 0 或 1 。注意,图片是以 0 为黑,但是 mnist 训练集中以 1 为黑,所以二值化时使用了 THRESH_BINARY_INV 进行反转。
但是这样是不能直接放入输入层的,原因有两点:
-
输入层要求 32 位浮点类型的数据,但是图片是以 8 位整数储存的;
-
数据的传入是通过指针的,所以要求数据连续存放,但是 Mat 的数据有可能是分散的。
所以,需要将数据放入一个连续的浮点类型数组里:
float data_ptr[784];//for data
uchar* p_data;
for( int i=0; i<28; i++)
{
p_data = img.ptr< uchar>(i);
for(int j=0; j<28; j++)
{
data_ptr[28*i+j]=(float)*(p_data+j);//get data and convert to float
}
}
这步创建了一个数组,并把图片中的数据转换为浮点数后放入数组,从而这个数组的指针可以作为数据的指针。
前传并取出预测值
终于到了最后的时刻了!
caffe_forward(net, data_ptr);
char query_blob_name[10] = "loss"; /* data, conv1, pool1, norm1, fc6, prob, etc */
unsigned int blob_id = get_blob_index(net, query_blob_name);
boost::shared_ptr<Blob<float> > blob = net->blobs()[blob_id];
unsigned int num_data = blob->count();
std::cout<<"data number:"<<num_data<<std::endl;
const float *blob_ptr = (const float *) blob->cpu_data();//get pointer to result
for( int i=0; i<num_data; i++)
{
cout<<*(blob_ptr+i)<<" ";
}
进行了一次前传后,概率已经在输出层里了。为了取出数据,首先要得到输出层的 blob,然后得到数据的指针,即 blob_ptr,这样就实现了图片到数字的映射。
总结
-
整个流程为:加载网络 -> 处理图片 -> 数据格式转化 -> 传入数据 -> 前传 -> 取出预测的概率。
-
主要问题在于数据格式的转化,要从图片的数据转化为 Caffe 可以处理的数据。python 中因为数据类型简单,所以比较方便;c++ 中数据类型很严格,要进行强制类型转化。