
ICRA 2019 RoboMaster AI Challenge 策略方案
ICRA RoboMaster AI Challenge 的核心在于策略的开发。从官方提供标准平台就可以看出,希望参赛队伍把重心放在策略。我们队使用的是传统状态机和强化学习组合的策略。状态机用于控制全局的策略,如何时开始比赛、何时补弹、何时使用强化学习等宏观行为。因为这些行为都有固定的模式,条件清晰,动作明确,用状态机可以快速地控制比赛的策略。强化学习主要用于局部的策略,本赛季我们只实现了追击的功能。因为追击的功能需要对敌方的行为快速作出反应,动作控制很复杂,所以用强化学习可以学到适合各种情况的策略,更加灵活。本文主要介绍用强化学习实现追击,具体代码。
模拟环境
部署强化学习算法之前,需要设计一个尽可能真实的模拟环境供模型训练。我们基于 OpenAI Gym 的 Top-down car 环境开发。Top-down car 模拟的是一辆车在公路上的行驶,我们沿用了它对车运动的控制,额外加入了 ICRA 真实比赛的场地边界和障碍块、子弹、补给区和 buff 区。主要参考的是 box2d 教程 及其 Python 接口。为了方便强化学习的训练,简化了真实场地:
- 忽略了车运动的加速度,而是通过直接设定速度的方式来改变运动,并且没有摩擦
- 忽略了装甲板,子弹只要击打到车就会产生伤害,两辆车相撞也会产生伤害
- 时间设为2分钟,而不是7分钟,防止双方无意义的对峙拖慢训练
- 初始弹量设为200,为了让模型专注于如何进攻
强化学习算法
最开始的技术提案里,我们设想的方案是用全局的地图作为状态,全局的目标点作为动作,血量优势作为奖励,使用 DQN 作为核心模型。然而,实际部署中遇到了如下问题:
- 无法把官方框架 RoboRTS 中的路径规划完全移植到模拟环境中,同样的目标点,模拟环境中的路径和实际路径可能不同
- 一旦识别不到敌方,输入的地图就只有自己的位置,就很容易陷入马尔科夫链的循环,实际效果就是原地打转,甚至静止不动
- 就算识别到了敌方,模型也很难学习到追击的策略,因为追击和造成伤害并没有直接的联系,需要通过射击子弹这个媒介
之后,我们又尝试了 PolicyGradient,最终使用了 ActorCritic,用激光雷达的扫描信号作为状态,底盘的运动作为动作,血量优势作为奖励,实现了追击的功能,接下来介绍各种加速收敛的技巧。
输入状态
使用激光雷达的扫描信号作为状态的灵感源于 ViZDoom ,这是一个在 FPS 游戏中使用强化学习的竞赛。既然光凭第一人称的界面就可以实现强化学习,一维的激光雷达信号也能包含足够的信息。使用激光雷达信号作为状态的好处在于:
- 缩小了输入规模,雷达信号是一维的,而全局地图是二维的
- 雷达信号可以直接获得,而全局地图需要 SLAM 建图才能获得
- 雷达信号更加直接,信号值表示对应角度离最近障碍物的距离
另外,为了加入敌方的信息,我们加入了另一个同样大小的数列,表示雷达信号对应角度上障碍物的类型,如果是敌方车的话,就设为1,否则0。所以,实际的输入状态是两个数列,一个是激光雷达的距离信号,另一个是对应角度的障碍物类型。
ActorCritic
核心的神经网络模型相当简单,如图: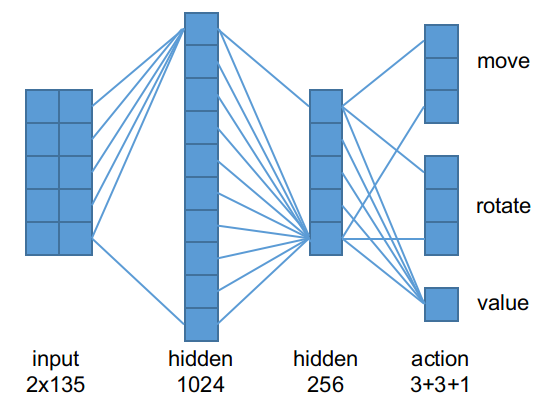
输入先扩展到1024维,然后收缩到256维向量,这个向量作为高级特征,分别输出3维的平移动作(对应左移、前进和右移)、3维的旋转动作(左转、不动和右转)以及 Critic 预估的价值。让 Actor 和 Critic 共享前几层的目的在于让他们共享信息,可以加速收敛。
加入先验
虽然目前的模型已经可以收敛了,但是收敛的速度相当慢,如果能够加入一些先验,可以收敛得更快。
首先考虑转向的动作。转向不会改变位置,所以没有避障的需求,但是要尽量对准敌方的方位,因为自动瞄准的视角有限。相关的输入状态就是第二条障碍物类型的数列。如果在左侧有敌方,就应该往左转;在右侧就往右转;在前方就不转。所以先验就是:
\[p_r = Softmax([\sum enemy_{left}, \sum enemy_{front}, \sum enemy_{right}])\]其中 $enemy_{direction} = [t_1, t_2, \cdots, t_n], t_i \in {0, 1}, i \in direction $
最终的动作就是:$ a_r = o_r + p_r $,其中 $o_r$ 是 Actor 的旋转动作输出。这样,Actor 只需要学习和先验动作的残差,也就是$a_r - p_r$,收敛起来很快。
同理,对于移动的动作,还需要考虑距离信号,避免撞墙,也就是尽量往距离远的方向移动,先验如下:
\[p_m = Softmax([\sum distance_{left}, \sum distance_{front}, \sum distance_{right}])\] \[+ Softmax([\sum enemy_{left}, \sum enemy_{front}, \sum enemy_{right}])\]其中 $distance_{direction} = [d_1, d_2, \cdots, d_n], d_i \in R^+, i \in direction $, $enemy_{direction} = [t_1, t_2, \cdots, t_n], t_i \in {0, 1}, i \in direction $
最终的动作就是:$ a_m = o_m + p_m $,其中 $o_m$ 是 Actor 的移动动作输出。Actor 只需要学习残差,收敛快。
优缺点分析
比起我们最初的技术提案,这个模型简单了很多,不过也能很好地实现追击的功能。其优点在于:
- 模型简单,易于理解,训练快,实车测试时反应快
- 加入了先验,训练收敛快
- 一旦识别到敌手,能很灵活地实现追击的功能
缺点在于:
- 先验也可能造成偏见,不能保证收敛到全局最优策略
- 实现的功能有限
- 没有记忆功能
- 如果不加限制,容易撞墙
- 没有识别到敌手时,依然会原地旋转,无法自主巡逻
实车测试
虽然在模拟环境里实现了追击功能,但是离在实车上实现还有很大差距,主要的问题在于:
- 如何和官方框架 RoboRTS 结合
- 如何避障
官方框架 RoboRTS 是基于 ROS 开发的,因此我们也用 Python 编写了一个 ROS 的节点,然后利用 ROS 的通讯机制,把激光雷达和自动瞄准的信息传给模型,再把动作传回给全局决策模型。另外,全局策略需要决定何时调用这个模型。从这个模型良好的追击性能看,我们选择了只在识别到敌手的时候,调用这个模型。但是这个模型的避障能力不强,因此我们又根据原始的激光雷达信号,编写了保护程序:当机器人在运动方向上离障碍物很近的时候,阻止移动命令的下达。解决了这些问题后,我们的模型终于在实车上运行成功了:
视频中,蓝车是人控制的,红车是自主运行的。首先全局策略会调用巡逻的程序,寻找敌手,此时枪口会不断左右摇摆来扩大搜索范围。识别到敌手以后,就会调用 ActorCritic 模型,此时枪口会瞄准敌方。ActorCritic 模型会引导模型追击敌手,视频中可以看到,红车识别到蓝车后,就一直往蓝车的方向靠近,但不是直线移动,而是看似无规律地运动,起到了躲避对方反击的功能。
总结
强化学习的确很强大,但是如何引导模型收敛是一个大问题,输入状态和输出动作的选择也很重要。刚开始我们选择了宏观的状态和动作,原以为能让模型学到最优解,但实际中模型往往收敛到静止的状态。之后我们就逐步简化模型的任务,使得模型成功地学习到了追击的策略。之后为了部署到实车上,我们又采用了手写的全局策略与强化学习的局部策略结合的方案。模拟环境和真实环境还是有很大差别,在目前强化学习还很难完全接手整个比赛的阶段,这种方案即可以有力地控制机器人的实际行为,保证运行的稳定,又可以充分发挥强化学习的灵活性。